Speech Recognition with VOSK-API
Introduction

And also VOSK gives us two types of models called the small model and the large model. We can replace our model with a that we most wanted. According to VOSK documentation, most small models allow dynamic vocabulary reconfiguration. Big models are static the vocabulary can not be modified in a runtime. You can download models here. A small model typically is around 50Mb in size and requires about 300Mb of memory in runtime. Big models are for the high-accuracy transcription on the server. Big models require up to 16Gb in memory since they apply advanced AI algorithms.
Currently supporting the following platforms: Supported languages and dialects
Linux on x86_64
Raspbian on Raspberry Pi 3/4
Linux on arm64
OSX (both x86 and M1)
Windows x86 and 64
Please note speech recognition tools didn’t give a perfectly accurate result. Sometime it will give some unexpected results. But the average accuracy of VOSK is very high.
Ok..! Let’s get started

Step 2: Install python3 and pip3
As mentioned in the documentation make sure that, you have the python 3.5 or above version installed. But highly recommend installing python 3.7 or above version when you trying to containerize your project. I faced lots of issues when using python 3.6. I could able to rectify those issues after starting with python 3.7.

Step 3: Install VOSK



This contains modules that support Python, C, C#, Java, NodeJS, Ruby, etc. But here, we’re only talking about the python module.
Ok..! Now all setup.
Speech recognition using an audio file
First of all, direct to the directory called “python” and to the directory “example” in it and see what files we have in it.
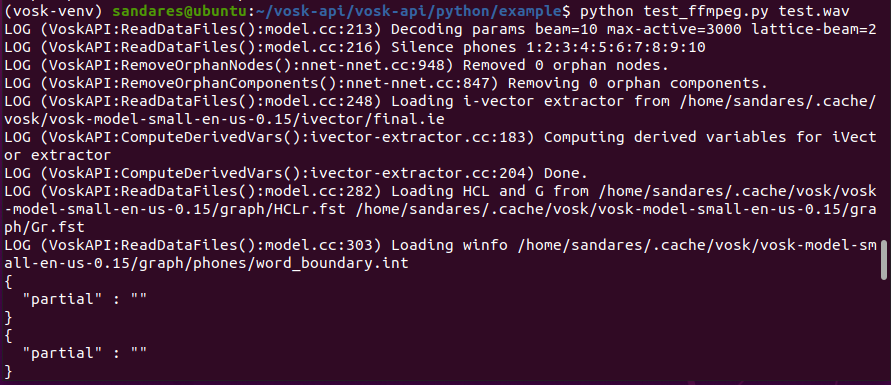
For this first example, I’m going to use the default test.wav file in the vosk project.
Note that, the first time that you run these commands, it will automatically download and set up the English small model by default.
1. Process a .wav file as text.
Note that, when using your own audio file make sure it has the correct format - PCM 16khz 16bit mono. Otherwise, if you have ffmpeg installed, you can use test_ffmpeg.py, which does the conversion for you.
This takes the audio file path as a command line argument. Simply run the following command and you can get the output

sudo apt update
If you have different linux environments try-out these with their default package managers.
Then simply run the following command giving the audio file path as a command line argument.
python test_ffmpeg.py test.mp4
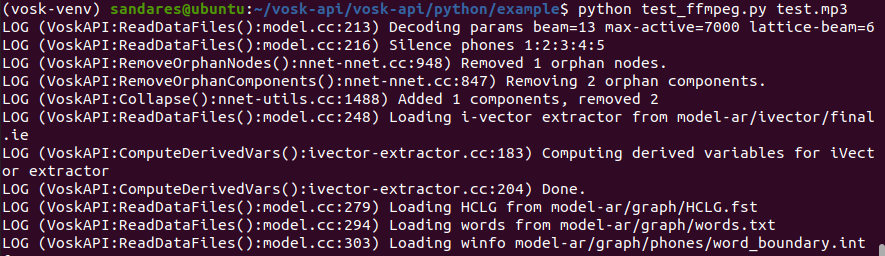
python test_ffmpeg.py test.mp3
python test_ffmpeg.py test.ogg
I tried-out this with .mp4, .mp3, .ogg files and I got the same results as previously.
Replace the default model with another language model
First, download the model into your project. Here, I’ll choose the Arabic language and I’ll use a small Arabic model. If you want to use a large model; no worries, follow these steps as it is.
After downloading, the model, unzip it and copy it to our project directory. (vosk-api/python/examples/). I renamed my model directory as “model-ar” for my convenience. Here is my project directory structure now.
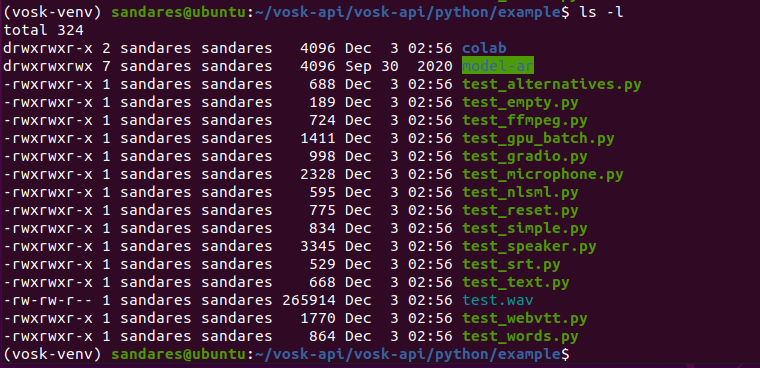

The answer is No. You can use files that only you need. Let’s take a look. First, I’ll create a directory in a different location. (location: ../../../)

Then, redirect to the directory where our files are located. Then copy the following files to the newly-created directory.
The Python file that you want. (for this example, text_ffmpeg.py)
Model directory
Audio file (test.mp3)
Then locate your new directory and see the directory structure.

These are the only things that you need. Then run again the following command and see the output.
python test_ffmpeg.py test.mp3
That’s very simple :)

Comments
Post a Comment